
TM (Translation Memory) – a database of previously translated content. Each time a segment of text (sentence, title, unit, list, etc.) is translated, translation memory stores the original source text together with the translated text as a pair. The translation is then automatically populated anytime the same source segment appears in the client’s content.
Translation memory promotes consistency across multiple projects and can significantly reduce the translation time for you and the translation cost for clients.
There are different types of TM matches and each of them will affect the project's cost:
| ICE match | 101% and 102% | In context exact match, shouldn't be reviewed or edited. There's no payment for strings marked as ICE match. |
| Leverage match | 100% | It's an exact match but in a different context. The string should be reviewed and you will receive a reduced payment for a string. |
| Fuzzy matches | 99-75% | A partial match that requires edits. The payment is reduced according to the match percentage. The higher the match, the lower the payment. |
| New words | 74% and less | Strings with 74% and below match should be used as suggestions only. You receive full payment for such strings. |
If a client uses TM, you’ll see the relevant info in the project header with a reduction breakdown:

Translation work for these projects should always be done in the online editor – the workbench. If there is an issue with the workbench, contact us via the Translators-BLEND Talk board. Translations performed offline (not using the workbench) will not be accepted.
In the online editor, a string that has a TM match is usually auto-populated to the translation section and marked according to the type of match:
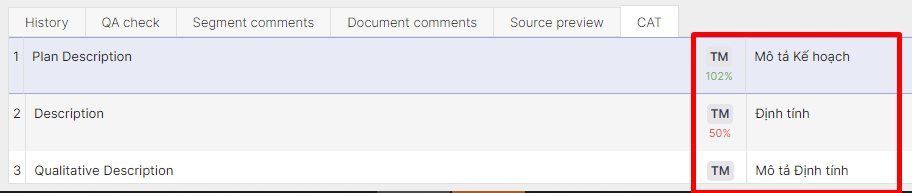
Important:
- Always use the suggested translation.
- If you strongly disagree with the TM suggestion, contact us with an example on the Translator-BLEND-Talk board (TBT) or you can leave a comment on a string in the editor directly.
- TM match should be prioritized over MT suggestion (if machine translation is enabled for a project).
Comments
0 comments
Please sign in to leave a comment.